从那时起,我便独自一人
照顾着
历代的星辰
L3DAS21: 声音事件检测与定位
L3DAS21 (L3D Ambisonic Sound Challenge) 是一项专注于声音事件检测 (SED) 和定位 (DOA) 的挑战,旨在推动基于3D声音场景的多任务学习研究。
主办方提出了两个任务:3D语音增强和3D声源定位与检测。这些任务旨在满足与真实和虚拟会议相关的现实需求。尤其在多说话者场景中,准确理解声音事件的性质及其在环境中的位置非常重要。需要了解声音信号的内容,并根据具体应用(例如远程会议、辅助听力或娱乐等)来最佳利用这些信息。 每个任务都包含两个独立的子任务:1个麦克风和2个麦克风的录音,分别包含由一个全向麦克风和由两个全向麦克风阵列采集的声音。据我们所知,这是首次将使用两个全向麦克风录制的声音数据用于机器学习研究。我们预期,当利用两个麦克风的双空间视角时,模型可以实现更高的准确性和重建质量。两个任务使用相同的音频录音,但目标完全不同,我们所进行的是TASK2。
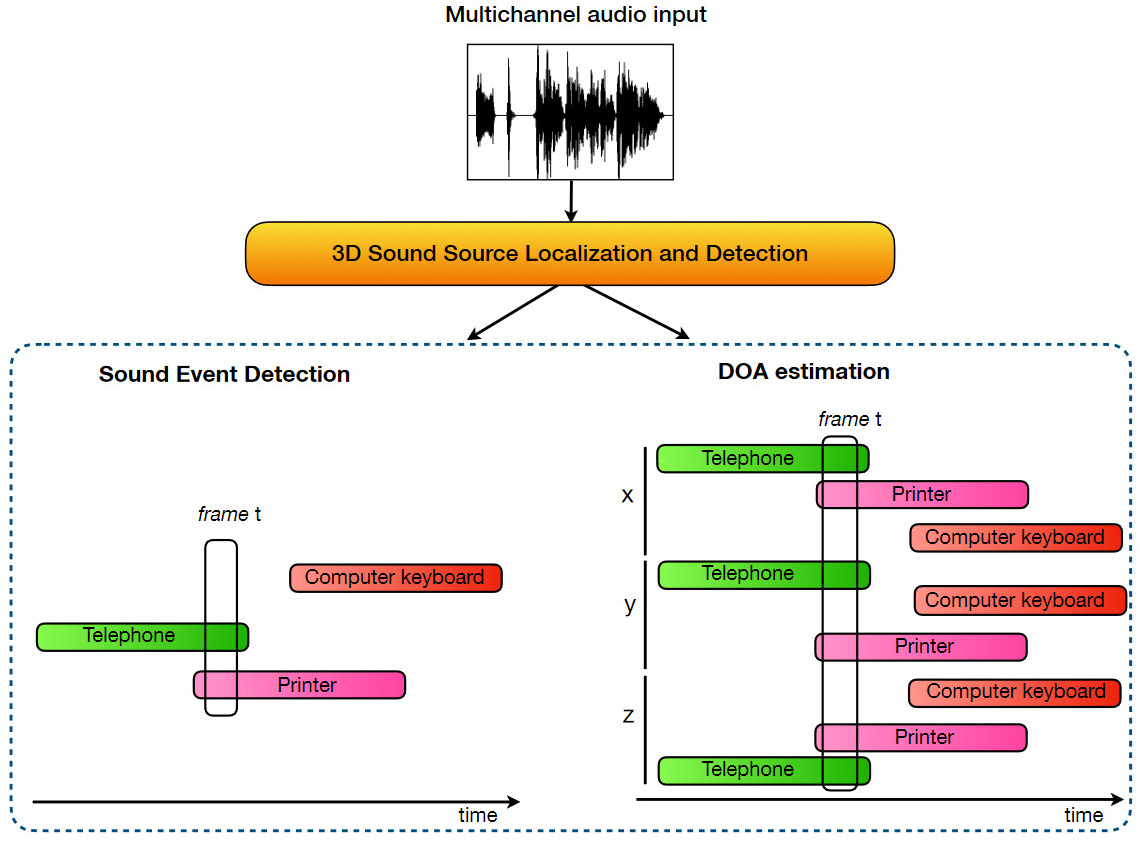
数据集
L3DAS21 的数据集中包含了多个任务场景,包括办公室和开放空间的模拟音频场景,背景噪声和目标声音事件混合在一起。音频数据以 Ambisonic B-format 存储,包含 4 通道的3D空间音频信息。参与者需要设计模型,从这些多通道音频中提取和预测声音事件及其位置。
The main characteristics of the L3DAS21 SELD dataset are:
- 900 1-minute-long data-points (a total of 15 hours)
- Sampling rate: 32 kHz
- Over 1000 sound event samples from FSD50K (14 sound classes)
- 252 RIRs positions collected in an office-like environment
- Separate sets with 1, 2 or 3 overlaps
评估指标
挑战的评估标准包括两个方面:
F1 score 用于衡量 SED 任务的表现,即模型在检测声音事件时的精准度和召回率。
Localization Error (LE) 和 Detection and Localization (DoaDE) 用于衡量声音事件定位任务的准确性,尤其是声音源的方向角度和时间的同步性。