从那时起,我便独自一人
照顾着
历代的星辰
自动调制识别(AMR)是现代无线通信中的关键任务,广泛应用于信号处理和频谱感知领域。本项目采用结合卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)及注意力机制的深度学习模型,对RML2016.10a数据集中的11类调制信号进行分类。
该模型首先利用残差卷积神经网络(ResNet)从输入的IQ两通道信号中提取时域特征,随后通过BiLSTM捕获序列信号的长期依赖性,并利用注意力机制聚焦于关键特征。最后,模型通过全连接层实现对11种调制类型的准确分类。
本文详细展示数据集的预处理步骤、模型架构设计及训练策略,并通过一系列可视化图展示信号的IQ分量及训练过程中的关键结果。本博客为深度学习在无线通信中的应用提供了有效的参考,适合对AMR及信号处理感兴趣的读者学习与借鉴。
关键词自动调制识别、深度学习、卷积神经网络、双向长短期记忆网络、注意力机制
一. 简介随着无线通信技术的快速发展,现代通信系统中频谱资源变得日益稀缺。为了更高效地利用频谱资源,自动调制识别(Automatic Modulation Recognition, AMR)成为了信号处理和频谱感知中的一个关键任务。AMR主要通过分析接收到的信号样本,识别出其调制方式,为后续的解调和数据处理提供基础。在传统方法中,AMR依赖于专家知识和手工设计特征,而随着深度学习的兴起,数据驱动的自动特征提取方法逐渐展现出更强的表现力和鲁棒性。
本项目采用了一种结合卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)和注意力机制的模型,能够高效地识别不同的调制方式。通过CNN提取信号的时域和频域特征,BiLSTM捕获信号的长期依赖性,并借助注意力机制聚焦于关键信息,我们的模型在RML2016.10a数据集上实现了良好的分类性能。本文将详细介绍模型架构设计、数据集预处理、模型训练和结果分析的全过程,帮助读者更好地理解深度学习在AMR任务中的应用。
二. 数据集本项目使用的是RML2016.10a数据集,它是一个经典的无线信号调制数据集,广泛用于自动调制识别领域的研究。该数据集由美国无线电实验室(RadioML)发布,包含多个不同信噪比(SNR)条件下的11种调制类型信号。每种信号都以复数形式存储,其中实部代表I分量(In-phase),虚部代表Q分量(Quadrature)。
数据集中的11种调制类型包括:BPSK、QPSK、8PSK、16QAM、64QAM、PAM4、CPFSK、GFSK、B-FM、DSB-AM和SSB-AM。每种调制类型的信号都包含1000个样本,其中900个用于训练,100个用于测试。数据集中的信号采样率为2.048MHz,每个样本的长度为128个复数点。信噪比范围从-20dB到18dB,每种调制类型的信号都包含不同信噪比条件下的样本。
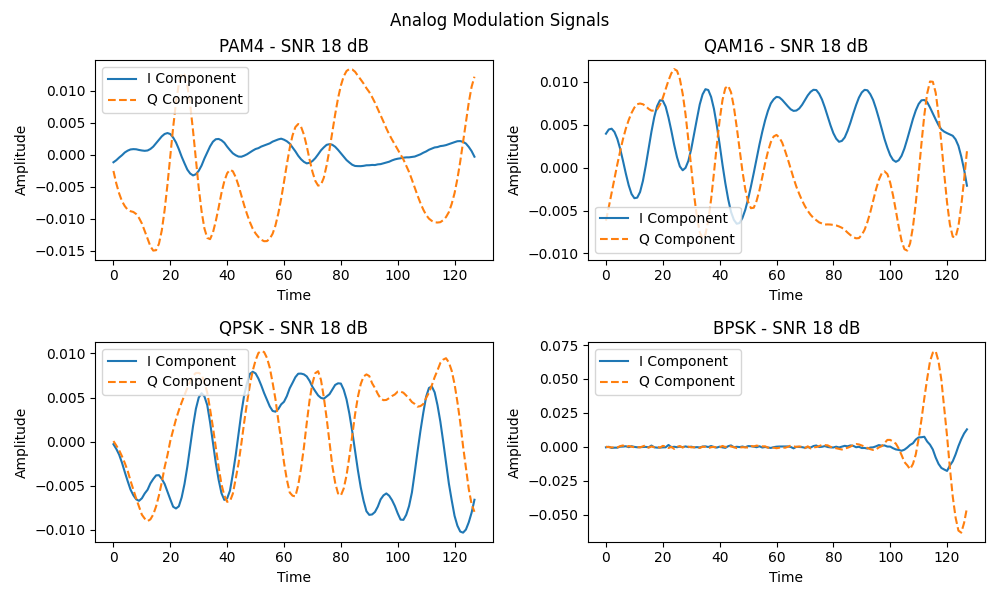
RML2016.10a数据集的多样性和现实场景的逼真性为模型的训练和评估提供了强有力的基础。通过对信号样本的预处理,我们可以将IQ分量转化为模型的输入特征,并借助深度学习算法进行自动调制识别。
三. 模型架构1.模型概述
ResNet-BiLSTM 是针对 AMR 任务的深度学习模型。它结合了卷积神经网络(CNN)的高效特征提取、双向长短期记忆网络(BiLSTM)的时序信息捕捉能力,以及注意力机制(Attention)的聚焦特性。该架构具有良好的噪声鲁棒性和处理复杂信号序列的能力,能够应对各种不同信噪比(SNR)的无线信号。
2.主要模块
CNN 特征提取器: CNN 通过一维卷积层和**残差块(Residual Block)**提取输入信号的时域和频域特征。模型包含两层残差块,每个残差块通过跳跃连接(shortcut connection)确保梯度顺利传递,有效避免了深层网络中的梯度消失问题。这种设计提高了模型对信号复杂特征的学习能力,增强了对不同调制方式的识别效果。
双向 LSTM 层: 在特征提取后,信号特征被输入到双向 LSTM 网络中。双向 LSTM 能够同时从信号的前向和后向时序中提取信息,对于时序依赖强的无线信号至关重要。这使得模型可以捕捉到不同调制信号的全局时间依赖性,从而增强分类性能。
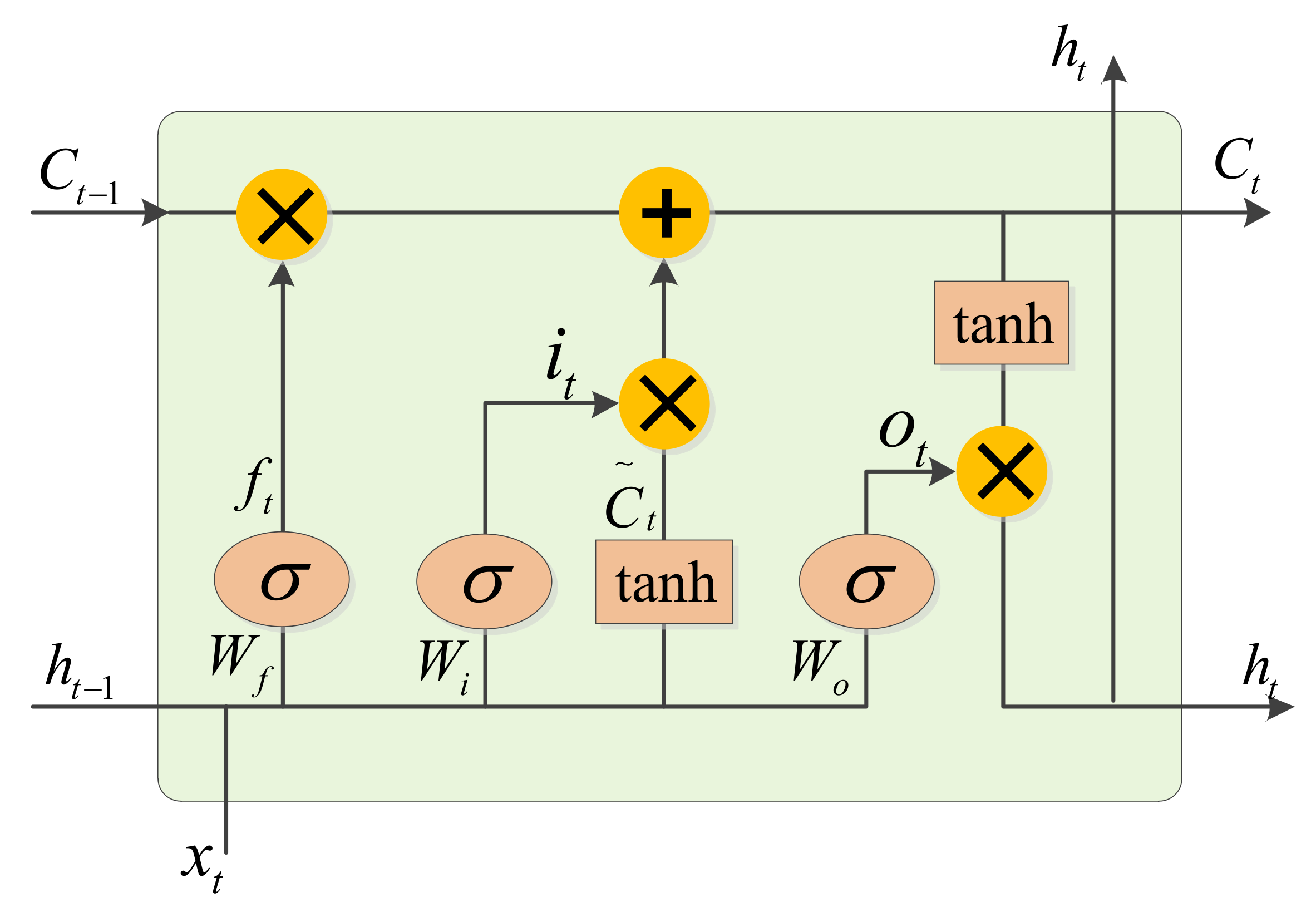
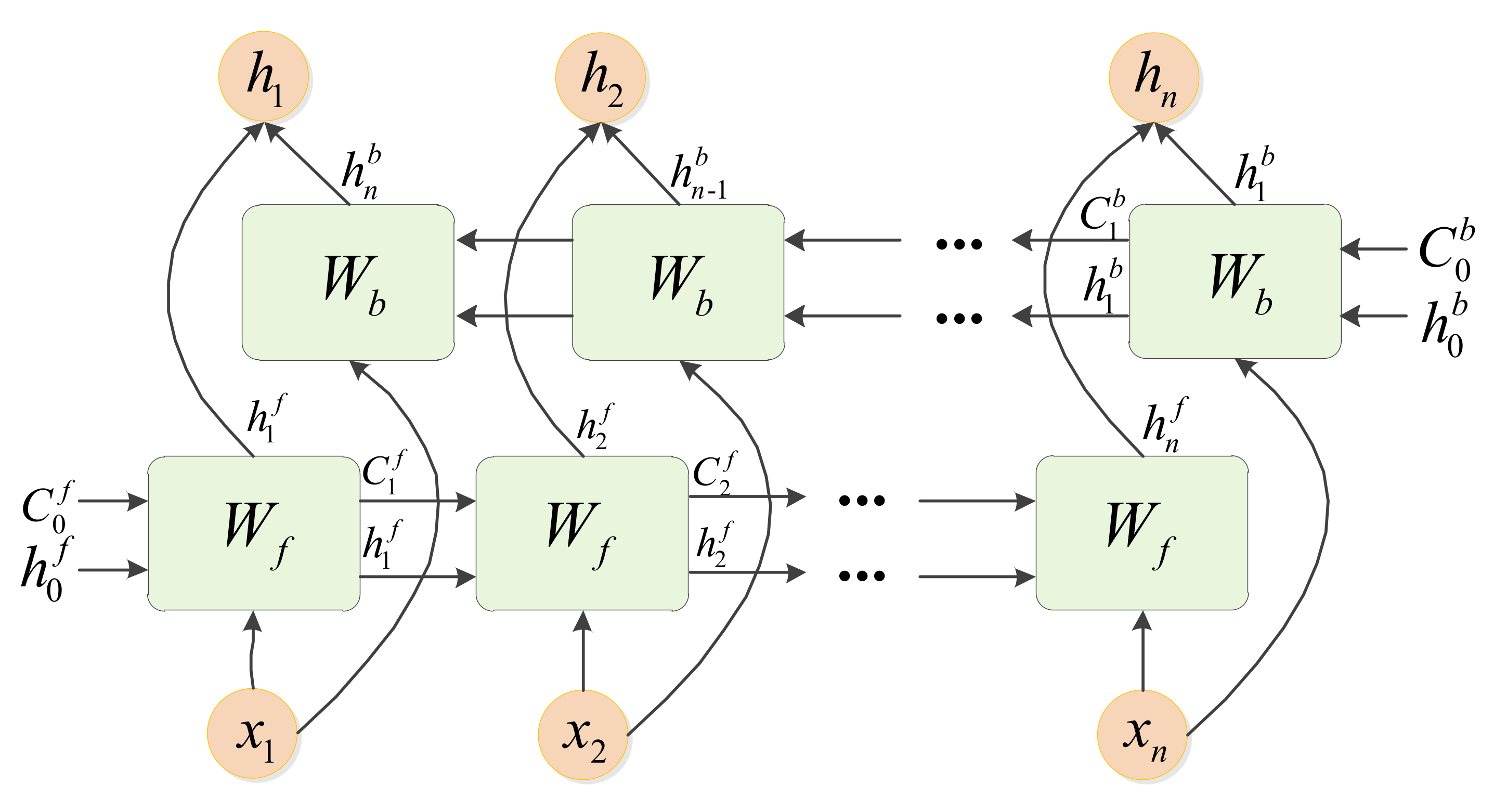
注意力机制: LSTM 输出的特征通过注意力机制进一步处理,Attention 机制为每个时序步长分配权重,使模型能够聚焦于信号序列中最具代表性的时刻。这不仅提升了模型的解释性,还增强了在复杂信号和噪声背景下的分类能力。
3.模型创新点
残差块(Residual Block): 残差块的引入解决了深层神经网络中常见的梯度消失问题。通过跳跃连接,确保信息能够在层与层之间更好地传播,使得即使在深层网络中,模型也能保持较好的学习效果。
BiLSTM 结合 Attention: 该模型通过 BiLSTM 捕捉信号的双向时序特性,并结合 Attention 机制对重要的时间步长赋予更高的权重。Attention 机制使得模型能够自动识别关键信号片段,从而提高整体分类准确性,尤其在长序列数据中表现出色。
四. 实验结果从训练结果来看,模型在不同SNR下的表现逐步提升,尤其是在较高的SNR下,准确率可以达到90%左右。然而,在低SNR(如-20 dB和-18 dB)时,准确率非常低,仅有10%左右,这是常见的现象,因为噪声对信号的影响在低SNR下非常严重。
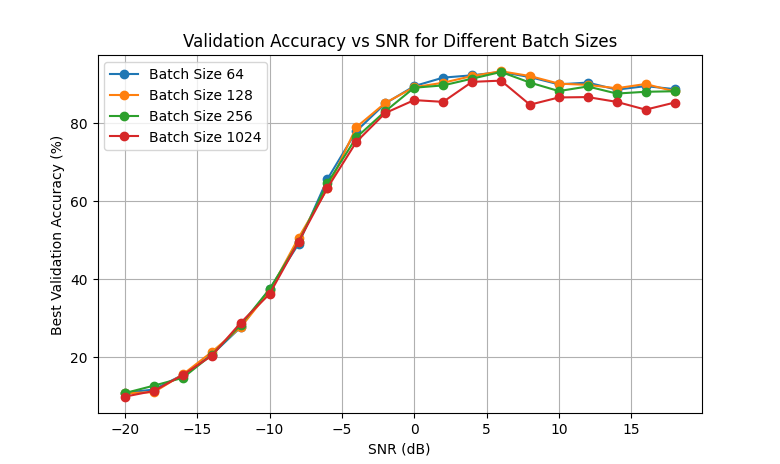
综合来看。SNR(-20 dB到-12 dB):在这些SNR下,准确率相对较低,主要因为信号中的噪声干扰过大,模型难以从中提取有用的特征。比如,-20 dB时准确率仅为10.77%,这接近于随机分类的结果(11类分类的随机准确率约为9.09%)。 中等SNR(-10 dB到0 dB):随着SNR逐渐升高,信噪比改善,模型对信号的识别能力增强。比如在0 dB时,准确率达到89.5%。 高SNR(2 dB以上):在SNR较高的情况下,模型几乎可以准确识别信号,最高准确率超过93%。
从6 dB开始,模型的准确率逐渐趋于稳定,大约在92-93%之间波动。这说明模型在信噪比改善到一定程度后,已经充分学会了信号的特征,达到模型的性能上限。 在SNR为6 dB之后,准确率开始出现轻微的波动和下降。这可能与模型的过拟合有关,在更高SNR下,训练数据的多样性不足,模型可能会过拟合到某些特定的高SNR信号特征。
五. 超参数调优在本项目中,超参数调优是提高模型性能的重要环节。针对批量大小、学习率、dropout率等参数进行了细致的调节,以下是具体的调优思路和实施细节。
批量大小(Batch Size): 批量大小是指在一次迭代中输入到模型中的样本数。较小的批量大小可以使模型更频繁地更新权重,从而提高模型的泛化能力,而较大的批量大小则能加速训练过程。在实验中,通过调整批量大小,我们选择了 64 作为训练中的批量大小,这在多个 SNR 条件下展现出良好的性能。
学习率(Learning Rate): 学习率是控制模型更新权重步伐的超参数。初始设置为 0.001,并使用 Adam 优化器。在训练过程中,加入了学习率调度器,以便在验证损失不再改善时自动降低学习率,从而提高模型的收敛性。这样的设置在提高模型准确性方面发挥了重要作用。
Dropout 率: 为了防止模型过拟合,模型中引入了 dropout 层。经过多次实验调整后,最终选择 0.3 的 dropout 率,这在多个 SNR 水平下均表现出较好的效果。这种设计有效降低了模型对训练数据的依赖,从而提升了其泛化能力。
此外,优化器的权重衰减(weight decay)设置为 1e-5,以控制模型的复杂度,防止过拟合。在训练轮次(epochs)方面,设置为 50 以确保模型有足够的时间进行训练和验证。
六. 结论本项目提出的ResNet-BiLSTM模型展示了深度学习在自动调制识别任务中的有效性和潜力。结合多种深度学习技术的模型架构,能够充分挖掘无线信号中的重要特征,进而提升分类性能。
通过对RML2016.10a数据集的实验,我们验证了模型在不同SNR条件下的鲁棒性和性能表现。在高SNR条件下,模型准确率可以达到93%以上,表现出色。在较低的信噪比(-20 dB和-18 dB)条件下,模型的准确率显著下降,显示出深度学习模型在处理噪声干扰较强的信号时的局限性。这提示我们需要探索更有效的噪声抑制技术或特征增强方法,以改善低信噪比条件下的识别能力。
在未来的研究中,我们将进一步探索更复杂的网络结构和优化策略,以及在实时信号处理中的应用场景,以推动 AMR 技术的更广泛应用。
注该项目并非课程项目,完全出自于我的个人兴趣。自2024年5月有了这一想法以来,经过断断续续的努力,直到9月份才取得初步成果。由于本人在学业上较为繁忙,精力有限,未能从更高的层次和更广泛的维度对模型进行全方位的评估和分析。如果未来有机会,我将继续深入研究该项目。所有源码已开源,欢迎各位朋友提出宝贵的意见和建议,共同探讨和改进。感谢大家的关注与支持!